Sometime last year, I started playing around with prototyping a card game. At its core, it’s a hidden-loyalty game strongly influenced by The Resistance and Battlestar Galactica, but with combat influenced Lunch Money. As such, it’s required a lot of tweaking for the little playtesting I’ve done.
I recently dug up and updated my prototype, throwing away long-removed cards and reprinting heavily marked-up cards.
This has all been a rather painless process because I chose to use nanDECK for printing my prototypes. This allowed me to manage my deck lists in spreadsheets, which I then feed into nanDECK whenever I want to do a printing. (And deck list management was a concern for me, since I had three decks–Loyalty, Player Actions, and Encounters.)
I won’t say nanDECK is a useful tool for every deck you need to prototype. There are other programs that will spit out printable cards from a CSV–likely much, much easier to configure. nanDECK’s configuration is rather esoteric, and some of it feels like it slowly evolved out of bolted-on user requests.
In part 2 I’ll talk about how to actually write these configurations. But for now, let’s talk about the reasons you would (and wouldn’t) want to use nanDECK.
Reasons I used nanDECK
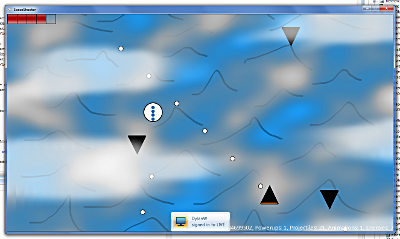
Testing card probabilities: My game contains multiple copies of the same card, so I wanted to be able to adjust the numbers to tweak the “feel” of the randomness (ideally, without having to print up cards). Fortunately, nanDECK has a “Virtual Table” feature that allows you to draw cards from a shuffled version of the deck.
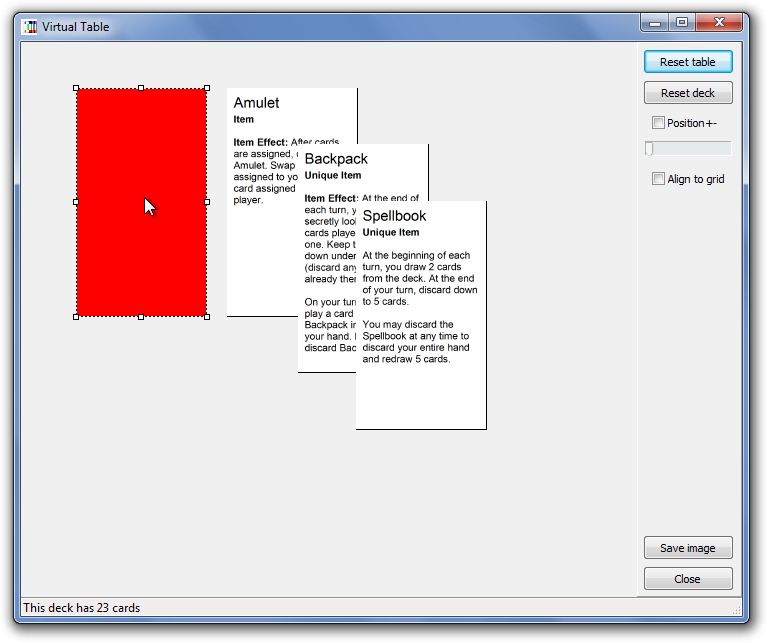
My own card layouts and spreadsheets: My Encounter cards don’t fit into a simple title-and-description format. Some (but not all) Encounter cards include some numeric values.
While I could simply embed these in one long description, I wanted to make them columns in my CSV file. I also wanted my card template to conditionally hide these fields (and their labels) if they were empty in the spreadsheet.
Custom card formats: For simplicity and uniformity, I prototype with perforated Avery business card templates. This is extremely convenient for me, so long as I can make the cards fit the template. (If I was using Word, this would be easier, but it would also require me to copy-and-paste a lot of cards.)
I needed to be able to force my cards into a non-standard 2″ x 3.5″ format, and (more importantly) ensure these cards were laid out matching the perforations.
Cases where nanDECK wouldn’t be useful
Simple title-and-text cards: If your cards don’t benefit from a custom layout, then it’s probably not worth wrangling nanDECK’s templating system.
Unique cards: If there will be one and only one copy of each card in your deck, nanDECK isn’t going to be worthwhile. You’re better off using something like word (even if trying to maintain your card list might be a bit awkward).
Anything beyond initial prototyping: If you’re adding card art or you’re no longer juggling card text on a regular basis, nanDECK is more complicated than helpful. At this stage, you’re better off laying out cards in a desktop publishing or graphics application.